


从CPU时代到GPU时代,工业软件行业需要GPU思维
行业新闻

2024.06.06
阅读量:999+

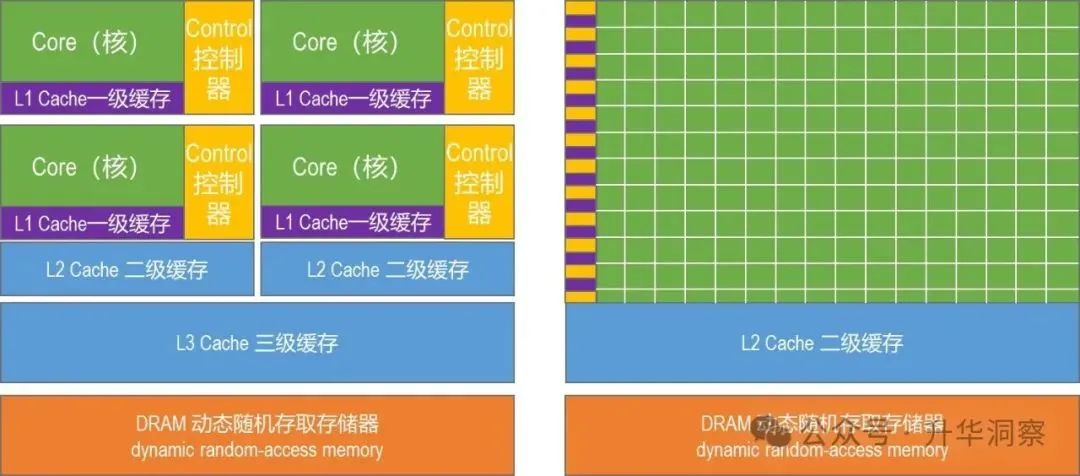
随着人工智能算法和GPU硬件的发展,计算机领域仿佛从CPU时代进入了一个新的时代——GPU甚至XPU的时代。在这个新时代里,规模法则(Scaling Laws)起到了十分重要的作用。CPU时代我们在设计算法或编写软件时,采用的是用复杂算法解决复杂问题的思维方式,好比用老教授的高超和复杂的知识和技能来解决问题,这就是CPU思维。

现在我们来到了GPU的时代,解决问题和思维的方式都发生了变化。过去需要一个老教授才能解决的问题,现在需要看看能不能将复杂问题拆解为若干简单单元,尝试用一万个小学生来解决?我们需要设计新的算法,利用更多的计算单元,而不是更复杂的计算单元。如果一万个小学生不够,那就用一亿个小学生来解决这个问题,如果还不够,就用一万亿个小学生来解决。这就是GPU时代的思维。当然,除了GPU之外,还有TPU、NPU等等,还有更多各种各样的处理单元,我们可以统称这些处理单元为XPU。现在我们在解决问题时,有了更多的选择,在设计算法时也有了更多的思维模式。包括工业软件在内,整个软件行业正处于巨变时代。无论设计新算法或改造旧算法,都需从CPU思维转变为GPU乃至XPU思维,需要选择最有效的算法和硬件,系统性地解决问题。毫不夸张地说,如今整个软件行业都在经历颠覆,每个算法都需要被重新审视,需要重新思考。

在人工智能前沿,一些新产品的开发团队寥寥数人便能颠覆整个行业,如OpenAI的Sora团队只有区区15人,Sora竞争对手Pika的核心开发团队只有4个人,但他们几乎颠覆了影视制作行业;ChatGPT-4o只有17人的研发团队正在颠覆人机交互方式。这足以说明从CPU到GPU乃至XPU时代,规模法则的颠覆力量有多强大。
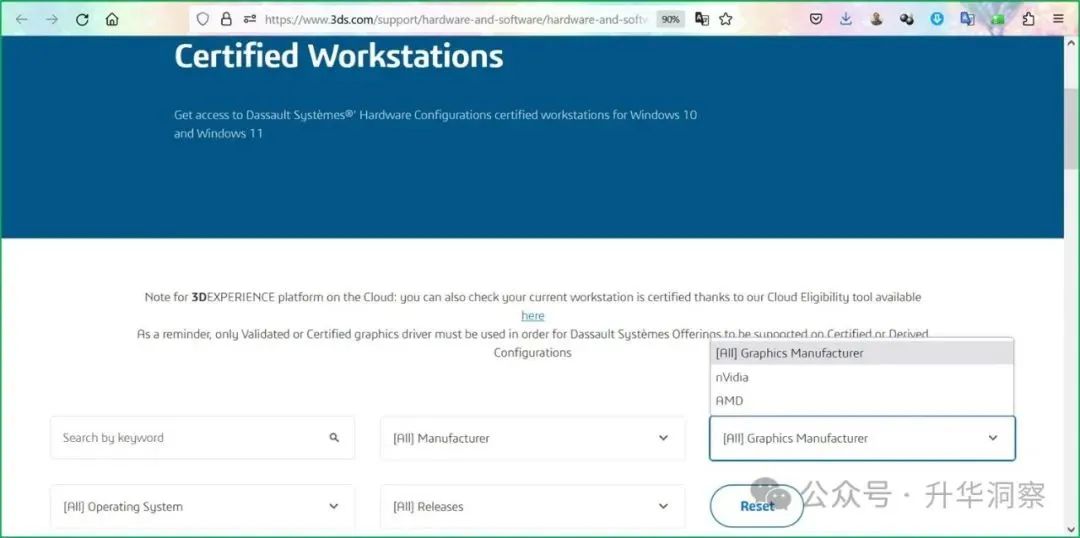
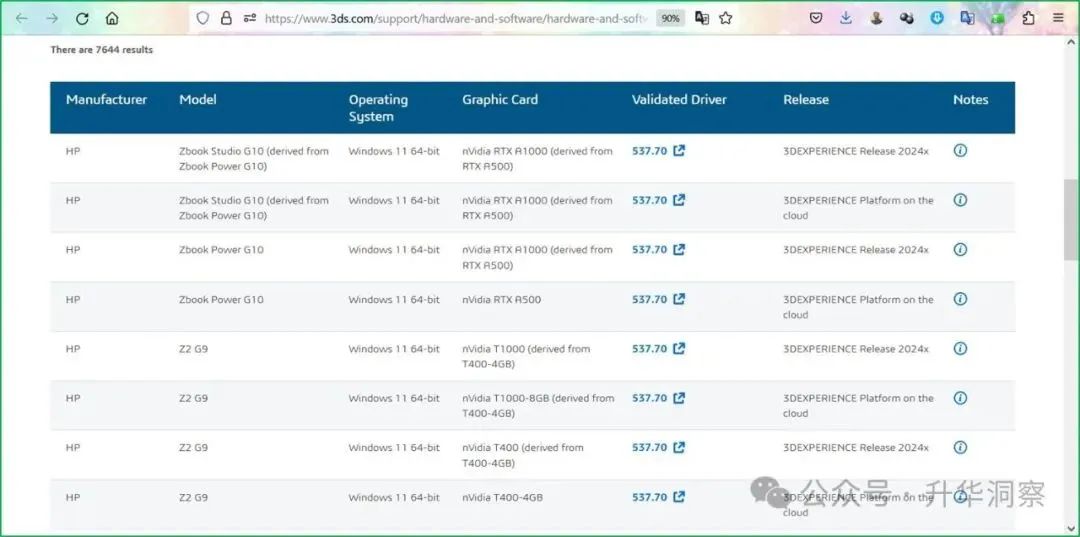
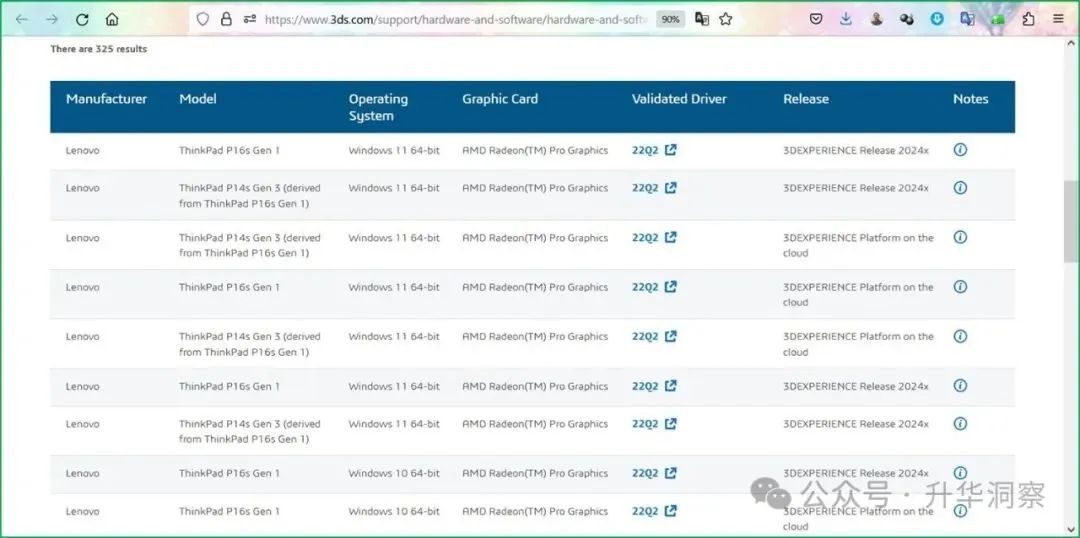
全球领先的工业软件厂商同样也在从CPU向GPU乃至XPU思维转变。本文将以达索系统为例,分享达索系统在软件研发过程中从CPU时代向GPU乃至XPU时代转型的一些思考和实践案例。本文分为五个部分:第一部分,介绍达索系统3DEXPERIENCE平台对GPU显卡的支持情况。第二部分,达索系统各个品牌对GPU显卡的支持情况。第三部分,GPU显卡制造商对达索系统各个品牌的支持情况。第四部分,GPU时代的案例分享。第五部分,从CPU到XPU转型下的工业软件行业。不难看出,工业软件行业正在朝向一个软硬一体化的未来。工业软件厂商与GPU乃至XPU硬件厂商紧密合作,以全栈最优的方式为客户提供最佳解决方案,以便更复杂、更精准、更快速地解决问题。一、3DEXPERIENCE平台对GPU显卡的要求从达索系统官方网站即可查询到3DEXPERIENCE平台认证的工作站型号,支持主流的nVidia显卡和AMD显卡。其中安装有nVidia显卡的工作站型号有7644种,安装有AMD显卡的工作站型号有325种。
nVidiaRTX A1000、A500属于Ampere架构的GPU,而T1000、T400则属于Turing架构的GPU。nVidia显卡架构以知名科学家的名字命名,从性能最新最强到最旧最弱依次为:Blackwell架构、Hopper架构、Ampere架构、Volta架构、Turing架构、Pascal架构、Maxwell架构、Fermi架构、Kepler架构、Tesla架构。
AMD的GPU架构演进主要体现在其从早期的TeraScale 3架构到后来的GCN(GPUCore Next)架构,再到最新的RDNA(RadeonDNA)系列架构。
二、达索系统各个品牌对GPU显卡的支持情况
达索系统各个品牌对GPU显卡均有不同程度的支持,从建模象限的CATIA、SolidWorks、GEOVIA、BIOVIA,到V+R象限的SIMULIA、DELMIA、3DVIA,再到社区协同象限的3DEXCITE等品牌,对GPU显卡的支持也逐年增强。以SIMULIA品牌的PowerFlow为例看对GPU支持能力的进步。在2023年发布的PowerFlow 2023x中,开始引入了GPU仿真的能力,第一版相当有针对性,只适用于特定应用,定位于概念车的空气动力学仿真,其他的功能还没有在GPU求解器上得到支持。

在最新的PowerFlow 2024x中, GPU支持功能不断增强,以便能够跨更多应用进行仿真。现在支持LRF(Rotating Reference Frames,旋转参考框架),用于轮子和风扇等事物的设计。更重要的是,PowerFlow 2024x支持多GPU,这意味着增强了运行更大案例的能力,使用户可以以更低的计算成本加速车辆空气动力学和空气声学仿真,来取代昂贵的 HPC 节点。目标工作流程包括:概念车空气动力学、空气动力学效率和操控性、驾驶室风噪声等。对于PowerFlow来说,仅支持单个GPU计算会受限于GPU内存,案例解算时需要适应GPU上的内存变化,对于大多数显卡来说,内存在20GB到80GB之间,而PowerFlow 2024能够在多个GPU上运行的能力消除了解算案例内存使用的限制。图中左侧的案例为使用 PowerFLOW 单GPU 求解器求解旋转 HVAC 风扇上的瞬态流动结构,右侧的案例为来自单 GPU PowerFLOW 求解器的 DriveAER 概念模型的瞬态空气动力学解决方案。
三、GPU显卡制造商对达索系统各个品牌的支持情况以AMD为例,从AMD官方网站上可以查询到AMD Radeon GPU显卡对达索系统产品的支持情况。
AMD专为达索系统CATIA/SIMULIA打造的Radeon Pro GPU具有三个主要特点:首先是利用 OpenCL技术加速仿真。为了充分利用 GPU 强大的并行处理能力,轻松进行工程分析和仿真,AMD 显卡针对 OpenCL进行了全面优化。Radeon PRO 显卡可对工程分析和仿真中的计算任务进行加速。而在过去,这些任务通常由 CPU 来完成。如今在 OpenCL版本的 达索系统SIMULIA Abaqus/CAE 中,GPU可充分发挥作用,大幅缩短执行结构与多物理场分析的时间。其次是VBO 支持。当CATIA配置为使用顶点缓冲对象 (VBO) 时,AMD显卡可带来出色性能。VBO 是位于图形处理器 (GPU) 显存上的缓冲存储区,CATIA 将顶点数据存储在这里实现直接访问,从而提高了图形处理能力。可用的 VBO 缓冲显存大小仅受限于显卡的物理显存大小。

第三是多屏显示实现卓越工作效率。近年来,产品开发工作流程发生了翻天覆地的变化。多款应用并用已经司空见惯,许多开发工作都需要同时进行设计、仿真、数据管理和协作。AMD Radeon PRO W7000 系列显卡具有四个 DisplayPort2.1 输出端口,使工程师能够通过单个显卡在多个高分辨率显示器上同时浏览多款应用和大型产品装配件,每路输出的分辨率高达 8K。用户能够以超高分辨率查看设计,全面提高设计准确性、逼真度和细节表现;还可以通过更多屏幕查看更多应用,大幅加快工作流程。

NVIDIA的网站上也同样有大量针对达索系统各个品牌及子品牌的支持资料。包括CATIA、SIMULIAAbaqus、CST Studio、PowerFLow、XFlow等。
四、GPU时代的案例分享
分享一个故事,讲的是雷诺集团与达索系统在AWS云平台上,借助于4000块GPU,以虚拟样机挑战物理样机的故事。

在汽车设计开发领域,物理样机一直是评估和决策过程中不可或缺的一部分。然而,随着技术的进步,雷诺集团和达索系统联合在AWS云平台上展示了一种创新的解决方案,通过分布式渲染技术,使用4000个GPU来挑战传统的物理样机。这项技术利用了达索系统的全球照明技术Stellar Physically Correct,基于NVIDIA OptiX SDK,实现了实时的高质量视觉效果,能够准确模拟车辆外观,做出数字审查决策。为了实时提供这种质量,雷诺需要将万亿次浮点运算规模的 HPC 容量与按需配置相结合。这一挑战的成功,为汽车行业的数字化转型提供了新的可能性。

上图中,左边是实际的照片,右边是仿真的结果,哦,错了,左边才是仿真的结果,右边才是实际的照片,问题是,你能分辨出哪个是真的吗?双兔傍地走,安能辨我是雄雌?

再来一张对比,左边是渲染的结果,右边是真实照片。哪个是哪个?重要吗?不是一样吗?

左边是实时渲染,右边是真实照片。来来来,来一局找不同!如果在本地计算进行实时渲染,大概的对比:
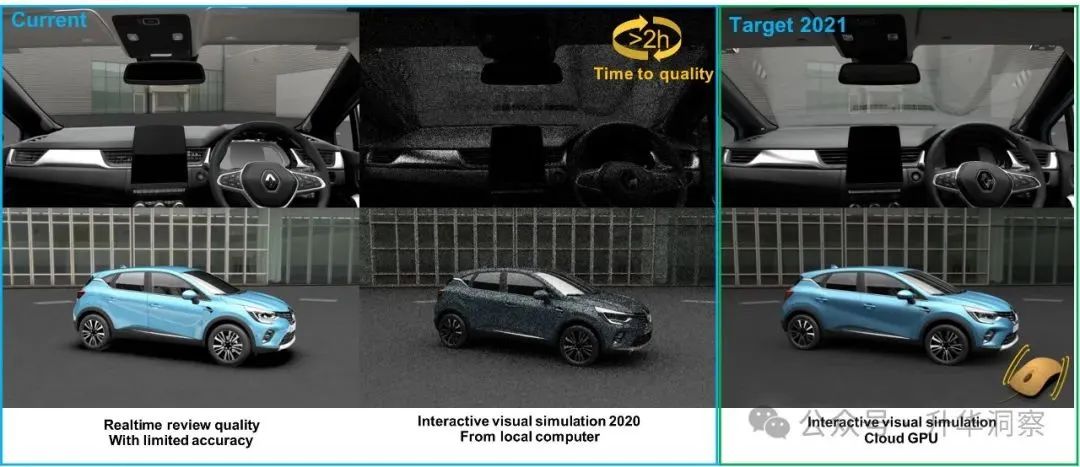
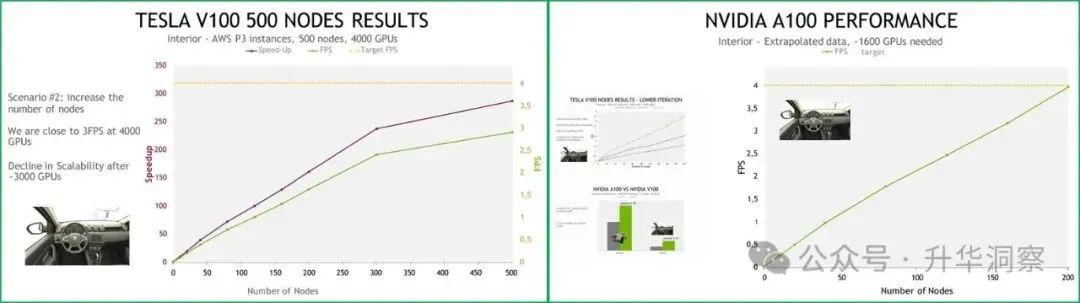
左边是不考虑准确性的可视化效果,和本地计算在交互情况下的视觉仿真结果。如果要得到准确的可视化效果,需要至少2个小时。而雷诺的需求是照片级4K分辨率(4096 x 2160)情况下,达到4fps,也就是每秒4帧。理论上来讲,这是本地算力的5万倍。这里说的本地计算,可不是一般的本地计算,本地的配置:Baremetal, 6 RTX Server, 24x NVIDIA QUADRO RTX8000解释一下,就是裸机服务器系统,六台服务器,每台服务器都配备了NVIDIAQuadro RTX 8000显卡,每台服务器都有4张NVIDIA Quadro RTX 8000显卡,总计24张显卡。基于NVIDIATuring架构和RTX平台,FP32性能为16.3TFLOPS,RTX-OPS为84T,能够快速处理大量数据和复杂模型。即使是这样的性能怪兽,要实现每秒4帧,仍然需要本地算力的5万倍!开始的时候尝试AWS P3实例,采用NVIDIAV100,200个节点,1600个GPU,未能达到4fps的性能。接着采用AWS P3实例,采用NVIDIAV100,500个节点,4000个GPU,达到了3fps的性能。可扩展性下降,也无法达到4fps的性能。最终采用了当时刚刚拿到的NVIDIA Ampere架构的A100,1600个GPU,才达到了4fps的性能。
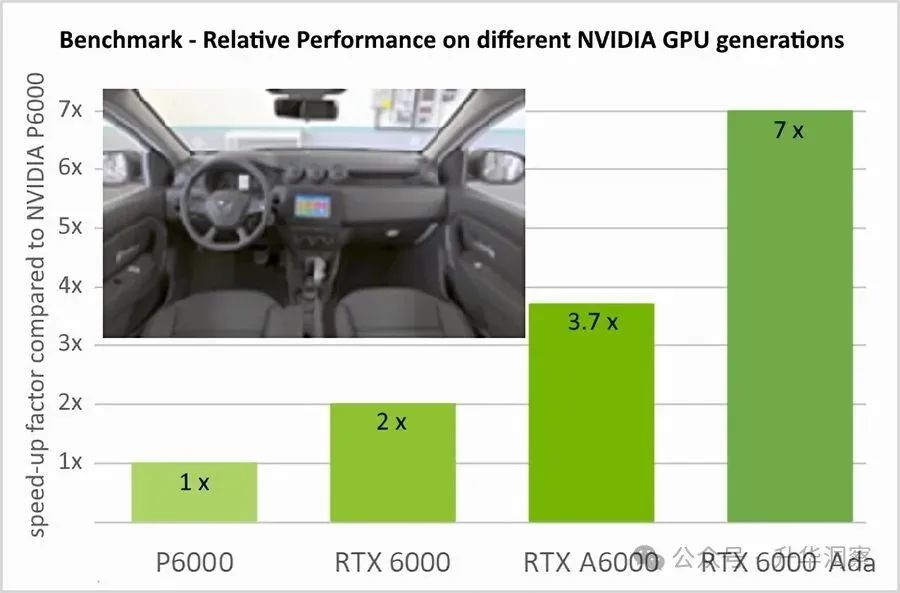
总结一下这个故事,雷诺与达索系统在AWS云平台上实现了一项前所未有的技术突破:全球首次使用500个节点和4000个NVIDIAV100 GPU进行实时全局照明(Global Illumination,简称GI)可视化。这一成就标志着汽车设计和审查流程的数字化转型,将对行业产生深远影响。这一突破性成就是团队协作的结果。基于对业务关键需求的驱动,雷诺积极参与了该项目;在达索系统研发团队的全力支持下,凭借AWS云提供的灵活性和计算能力以及NVIDIA在技术开发、软件和硬件方面的贡献,多因素共同促成了这一壮举。这一合作模式展示了不同领域领导者之间的协同效应,以及应如何通过合作解决复杂的技术挑战。在全局照明的复杂性方面,一个关键的认识是,它与多边形的数量无关。相较于外部场景,内部场景在计算上更为复杂。这是因为内部场景需要处理更多的材料、更多的光线反弹和更多的像素计算。这一发现对于优化渲染算法和提高计算效率具有重要意义。在使用大量计算节点进行分布式渲染时,团队发现了所谓的“节点数量平台期”。这是由于用于将工作分配给集群机器的平铺算法所导致的。随着工作负载的不断分割,GPU出现资源饥饿的风险也随之增加。在内部场景中,当节点数量超过350时,这种平台期开始显现。基于这一概念验证,团队设定了新的目标:提供每周1到2次、每次2小时的审查;使用275个节点,每个节点配备8个A100 GPU(总计2200个A100);以及实现至少4帧每秒的4K、2048样本的首帧渲染。达索系统 CATIA实时渲染的目标是在视觉质量上不妥协,但在基础设施上提供充分的灵活性,以达到支持决策的一流质量和性能。

达索系统全局照明渲染器 Stellar Physically Correct 使用在 GPU 或多核 CPU 等高性能设备上运行的硬件加速软件库,可有效生成最高质量的视觉模拟、渲染图像和视频。达索系统公司为企业和个人提供虚拟宇宙。通过这些宇宙,可持续创新变得可触摸,用户可以在生产之前模拟产品的外观。利益相关者可以在产品制造之前很好地评估、改进和市场化新产品的吸引力。STELLAR在两种不同需求的场景中发挥着关键作用:在交互式建模和审查场景中,用户可以追求具有最高互动性的可靠渲染结果;在其他情况下,可快速制作多个高保真图像或视频。为了满足这两种情况下对高度真实和可靠渲染的需求,STELLAR采用了基于路径追踪的渲染技术,并结合了光线追踪和光晕光子技术。路径追踪器通过追踪大量光线穿过虚拟场景来模拟光与物质的相互作用。这个过程考虑了表面的几何光反射和光通过几何体积的散射。解决这些模拟需要精心选择的渲染算法和硬件加速的软件库,这些库可以在单个机器上本地执行,或者在需要更多计算能力时,在计算机集群上远程执行。为了获得最佳的渲染性能,STELLAR建立在由领先的硬件供应商和达索系统合作伙伴提供的性能优化软件库这一强大基础之上,以达到提高每个系统性能的目的。
在CPU渲染方面,STELLAR利用了Intel oneAPI渲染技术的最新成果,包括多线程Threading Building Blocks技术、Intel优化的硬件光线-三角形相交库Embree、Intel的深度学习AI去噪器OpenImage Denoise等。

这些库与精确的渲染算法相结合,使得CPU和CPU集群的渲染性能非常有竞争力。在高性能计算(HPC)中心和客户的测试中,STELLAR显示出了出色的可扩展性。特别是拥有100多个节点或等效的数千个CPU核心的CPU集群,可以使用户从交互式和批量渲染中受益。在GPU渲染方面,STELLAR也在NVIDIAGPU上运行,许多情况下其渲染速度超过了CPU。这种效率基于利用NVIDIA提供的各种库,包括CUDA用于在GPU上高性能执行通用代码,如材质着色;OptiX用于硬件优化的光线-三角形相交,以在不同的NVIDIAGPU上实现最佳的光线追踪性能。NVIDIA OptiX也用于高性能和高质量的图像去噪。STELLAR为达索系统的各种产品提供渲染库,包括3DEXCITE DELTAGEN、3DEXPERIENCE平台、HomeByMe和SolidworksVisualize等。

雷诺和达索系统的这一合作项目不仅展示了虚拟样机技术的巨大潜力,也为汽车设计和制造的未来指明了方向。通过实时全局照明可视化,雷诺能够在数字环境中准确地评估车辆的外观和性能,从而加速产品设计和市场响应。这一技术的进一步发展和应用,预示着汽车行业将进入一个更加高效、灵活和创新的新时代。随着技术的不断进步和优化,我们有理由相信,虚拟样机将逐渐取代物理样机,成为汽车设计和审查的主流工具。
五、从CPU到XPU的转型
当我们在设计算法以解决复杂问题时,不必也不应该固化在CPU思维之上,或者说解决每一类问题,为了得到最高的效率,需要同时考虑包括硬件XPU和算法在内的全栈优化。当然我们要首先了解,包括CPU和GPU,到底现在还有哪些种类的处理单元?让我们先从APU到ZPU找一遍。APU(Accelerated Processing Unit):APU是一种将 CPU(中央处理单元)和GPU(图形处理单元)组合到单个芯片上的处理器。这意味着它无需单独显卡即可处理一般计算任务和图形密集型任务。这可以降低计算机系统的成本和功耗。APU 通常用于笔记本电脑和其他小型设备,其中空间和功耗是重要的设计考虑因素。APU也常用于经济型游戏电脑,与单独的 CPU 和显卡相比,在芯片上包含 GPU 可以节省成本。
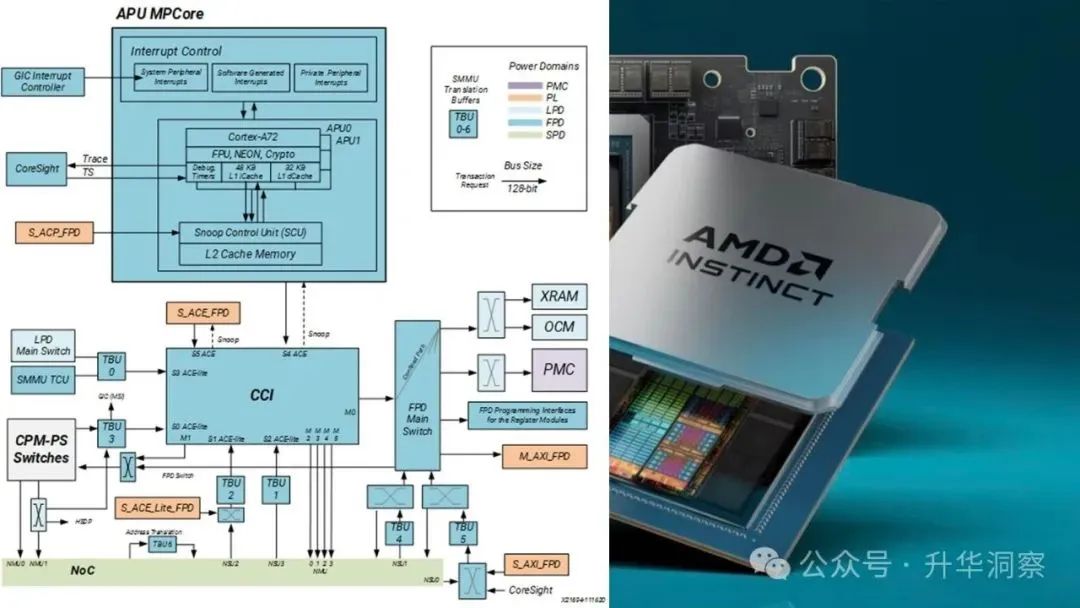
BPU(BrainProcessing Unit),一家名为地平线的公司开发的智能计算架构,具有领先的深度学习和决策推理算法开发能力,可将算法集成在高性能、低功耗、低成本的智能计算方案上;同时自主设计研发了创新性的智能计算架构BPU(BrainProcessing Unit),提供设备端上软硬结合的智能解决方案。
CPU略。DPU(Data Processing Unit,数据处理单元)是一种专门设计用于处理数据中心中网络、存储和计算任务的硬件加速器。它是以数据为中心构造的专用处理器,采用软件定义技术路线支撑基础设施层资源虚拟化,支持存储、安全、服务质量管理等基础设施层服务。DPU的主要功能包括数据传输、规约、保护、压缩、分析和加密等。它旨在高效处理数据中心内的大规模数据工作负载,减轻CPU负担,使其能够更好地处理其他类型的计算任务。DPU被认为是与CPU和GPU并列的第三种处理器,是现代计算中的重要组成部分。它不仅具备CPU的通用性,还结合了可编程的数据加速引擎,能够提供额外的安全层和特定的网络及数据中心基础设施功能。

图:NVIDIA DPUEPU(Embedded Processing Units)
嵌入式处理单元是专为特定行业设计的高性能、可靠的计算平台。VersaLogic公司生产的EPU产品具有多种优势和特点,适用于工业控制、军事和医疗等领域。根据VersaLogic的定义,EPU是一种高度集成的嵌入式计算机系统。VersaLogic旨在开发更小、更轻、功耗更低的系统,同时满足严格的监管标准。这些系统通常采用单板计算机(SBC)的形式,具有高度的灵活性和扩展性。总之,VersaLogic的EPU是一种高度集成、灵活且可靠的嵌入式计算平台,适用于需要高性能和可靠性的各种应用场景。
此外,华硕也定义了EPU,在主板相关技术中,EPU代表“Energy Processing Unit”,即能耗调控单元。它的主要功能包括节能、降噪和超频。这表明EPU是一种旨在提高电脑性能同时减少能耗和噪音的技术。FPU(Floating Point Unit)即浮点运算单元,是一种专门用于执行浮点数运算的处理器部件。浮点数运算包括加减乘除、开方等操作,主要用于处理带有小数部分的数字。自从486处理器以来,英特尔将FPU集成在CPU内,使其成为CPU进行浮点运算时的主要组成部分。FPU不仅限于传统的CPU,还可以存在于其他类型的处理器中,如ARMCortex M4中的FPU。GPU略。HPU(Holographic Processing Unit,全息处理单元)是微软为其HoloLens设备专门设计的一种集成电路芯片。HPU是一种ASIC(Application-specificintegrated circuit),即特定应用的集成电路。它与CPU和GPU共同工作,专门用于处理全息图像和数据。HPU的架构与传统的CPU和GPU不同,它开创了AI/AR领域芯片的新范式。HPU能够处理深度信息,并生成周围环境的三维场景,这对于实现高级增强现实(AR)和人工智能(AI)应用至关重要。例如,在HoloLens中,HPU可以捕捉并处理来自两颗深度摄像头的数据,从而生成高清晰度的全息影像。

IPU(Infrastructure Processing Unit,基础设施处理单元)是英特尔推出的一种高级网络设备,旨在通过专用的可编程内核来加速和管理基础设施功能。IPU具有强化的加速器和以太网连接,能够提供全面的基础架构卸载功能,从而提高CPU利用率和性能。IPU的主要目的是减轻中央处理器(CPU)的运算负担,从而释放更多的效能,使用户能够更有效地利用IT资源。它可以从主机分载整个基础架构堆栈,并控制主机与该基础架构的连接方式,为服务提供商提供额外的安全层和控制。
JPU(JPEG Processing Unit)是指JPEG 图片处理单元,主要负责JPEG 和MJPEG 的编解码功能。JPU 在图像处理,特别是在需要高效率和低延迟的应用场景中,如视频监控、智能手机摄像头等起着至关重要的作用。
JPU的主要任务包括对JPEG 格式的图像进行压缩和解压,以及执行其他相关的图像处理操作,如缩略图生成、缩放、旋转和过渡效果等。这些功能使得JPU在多媒体设备中非常重要,因为它们可以显著提高图像处理的速度和效率。
KPU(Knowledge Processing Unit,知识处理单元)是由Maisa公司开发的一种新型软件框架,旨在显著提升大型语言模型(如GPT-4和Claude)的推理能力。KPU通过作为知识管理和处理的GPU,优化数据处理,从而增强了这些语言模型的推理能力。KPU的架构包括三个主要组件:推理引擎(连接的大型语言模型),该引擎规划解决问题的步骤;数据处理单元,负责执行具体的数据处理任务;这种架构使得KPU不仅仅是一个简单的加速器,而是一个全面的知识处理平台,能够在多个层面上提升AI系统的性能。
LPU(Language Processing Unit,语言处理单元)是Groq公司开发的一种专门用于AI推理的硬件加速器。Groq成立于2016年,是一家位于硅谷的初创公司,由前谷歌员工Jonathan Ross创立,他是Google TPU(张量处理单元)的主要发明者。Groq的LPU在性能、速度和能效方面表现出色。其LPU推理引擎是一个硬件和软件平台,能够提供卓越的计算速度、质量和能源效率。LPU特别适用于计算密集型应用,如AI语言应用程序、音频、语音、图像处理、视频和科学计算等。Groq的LPU利用了创新的硬件架构设计,并配套了强大的编译器,这些技术使得LPU在AI推理中具有显著优势。此外,LPU内部使用静态随机存取存储器(SRAM)作为缓存或工作内存,以提高数据读写和处理速度。Groq的LPU在市场上引起了广泛关注,尤其是其与英伟达GPU的竞争。据报道,Groq的LPU在推理速度上比英伟达GPU提高了10倍,而成本仅为其十分之一。这种高性价比使得Groq的LPU在AI推理领域具有巨大的潜力和市场竞争力。
MPU(Micro Processing Unit,微处理器单元)是一个集成了多个CPU的芯片,用于并行处理数据。通常其上不集成RAM和ROM等设备。在早期,MPU是指单一的一颗芯片,而芯片组则由一组芯片构成,例如北桥(North Bridge)和南桥(South Bridge)。然而,现代的MPU通常指的是微处理器,它可以包含多个核心,并且具有较高的设计灵活性和性能。
NPU(Neural Processing Unit,神经处理单元)是专门为人工智能深度学习算法设计的半导体芯片。三星电子在这一领域进行了大量的研发工作,以提升其产品在AI性能上的竞争力。三星的NPU技术被称为“AI芯”,它能够同时进行多项计算,从而提高AI功能的完成速度。这种技术特别适用于AI深度学习和演算,因为这些任务需要同时处理上千个数据点。例如,三星的Exynos 9820处理器集成了NPU,其AI性能相比前代产品提升了7倍,并且可以增强从照片到AR的各种应用。
OPU(Optical Processing Unit,光学处理单元)是LightOn公司的一种创新的光子AI加速器芯片,专为非冯·诺依曼计算而设计,能够在大规模上进行高效计算。该技术首次将光子技术应用于市场上的AI加速器中,具有显著的性能优势。LightOn的OPU已经在欧洲的数据中心进行了测试,并且在全球顶尖的超级计算机中得到了实际应用。这种集成不仅展示了OPU在实际应用中的潜力,还表明了其在未来计算领域的重要性。
PPU(Physics Processing Unit,物理运算处理器)是一种专门用于模拟物理计算的处理器,主要用于沟通虚拟电子世界和现实世界中的物理现象,使得图像更加真实和贴近现实。PPU通过高效的物理计算来增强虚拟环境的真实感。与CPU和GPU不同,CPU主要用于提高运算速度,GPU侧重于图像效果的提升,PPU则专注于实现更为精确的物理模拟。
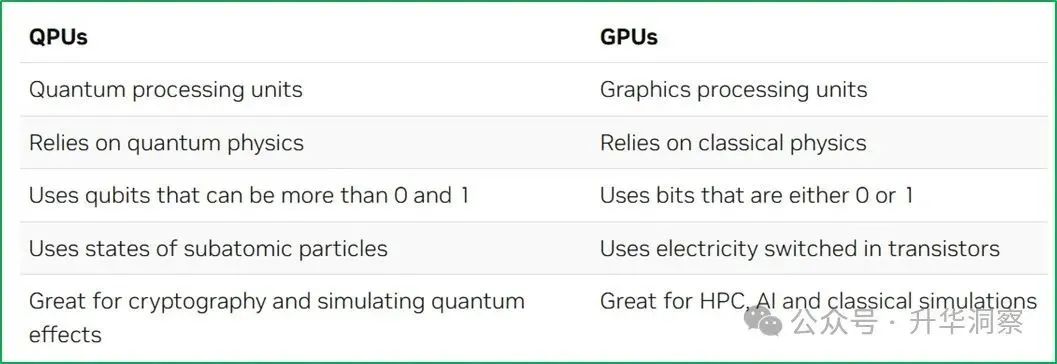
QPU(Quantum Processing Unit,量子处理单元),利用电子或光子等粒子的行为来进行特定类型的计算,其速度远快于传统计算机的处理器。QPU的工作原理基于量子力学的基本概念,如叠加(superposition)和纠缠(entanglement)。叠加是指一个粒子可以同时处于多种状态,这使得QPU能够在一次操作中处理多个数据,从而大幅提高计算效率。此外,QPU还依赖于量子门(quantum gates)来操纵量子比特的状态,类似于经典计算机中的逻辑门。QPU的设计和实现需要非常低的温度,在技术实现上通常使用超导体和超流体来达到这一目标。这些材料在超低温下表现出量子力学效应,使得电子可以毫无阻力地穿过它们,从而实现高效的量子计算。
RPU(Real-time Processing Unit,实时处理单元)是一种专门设计用于处理实时数据和实时决策的硬件单元。它能够高效地进行数据采集、分析、处理和响应,以满足对实时性要求较高的应用场景要求。RPU通常具备高性能、低延迟和可靠性等特点,可以处理大量的数据并快速做出决策。在实际应用中,RPU可以广泛应用于多个领域,例如个人电子产品(如穿戴设备、头戴设备等)、工业领域事件监测等。此外,RPU也被用于汽车驾驶员辅助与安全系统、无线和有线通信、数据中心以及连接与控制等多种应用领域。
SPU(Secure Processing Unit,安全处理单元)是一种专门设计用于保护数据隐私和安全的计算设备。它通过硬件方式实现整个数据计算过程中的安全可信,确保在计算过程中用户的私人数据得到有效保护。
TPU(Tensor Processing Unit,张量处理单元)是Google为机器学习和深度学习设计的一种专用芯片(ASIC)。其主要目的是加速神经网络的计算,特别是在处理大规模数据时的效率和速度。TPU的核心架构是张量核心(Tensor Core),这种架构能够同时处理多个张量运算,从而实现高效的并行计算。具体来说,TPU内部的计算部件包括矩阵乘单元(Matrix Multiply Unit),其输入是权重数据队列和统一缓冲(Unified Buffer),输出则是累加器(Accumulators)。与传统的GPU相比,TPU在神经网络推断方面具有显著的优势。这得益于其专注于神经网络推断的设计,使得量化选择、CISC指令集、矩阵处理器和最小设计成为可能。此外,TPU的设计思路是完全按照深度学习一个层(Layer)的计算流程来设计的,这使得其在处理复杂的神经网络时更加高效。
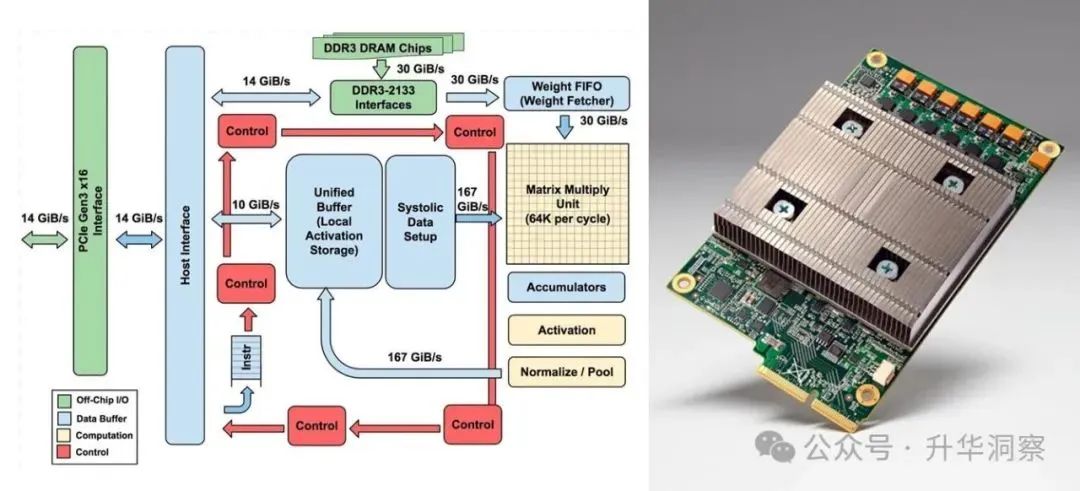
UPU(Unified Processing Unit,联合处理单元)是一种新型的处理器架构,旨在将CPU和GPU的功能集成到单一芯片中,目标是提供更高的能效比和更好的并行计算性能。
VPU(Vision Processing Unit,视觉处理单元)是一种专门设计用于高效处理图像和视频数据分析的处理器。其主要功能是处理大量的视觉数据,因此在各种AI框架和应用中扮演着关键角色,如数字相机、机器人和医疗技术等。VPU具有硬解码功能,可以减少CPU的负荷,从而提高系统的整体性能。此外,VPU还集成了编码器和解码器功能部件,用于加速图像和视频数据的编解码过程。这使得VPU在云端和终端应用场景中都有广泛的应用前景。在具体应用方面,VPU可以用于视频会议中的自动构图、眼球跟踪、虚拟头像/人像、姿势识别等功能。此外,VPU还能够处理背景模糊、视觉美颜、声音美化(音频降噪)、视频降噪、图像分割等端侧AI应用场景。英特尔的Movidius VPU是一个典型的例子,它旨在加速电脑上的人工智能工作负载,提高系统响应能力、效率和AI计算性能。这种高能效的VPU特别适合移动端应用,因为它可以释放额外的CPU/GPU资源,从而延长电池续航时间。

WPU(Wearable Processing Unit,可穿戴处理器),专门为可穿戴设备和物联网市场量身定制的一种处理器,集成了GPU、CPU等不同IP核,以满足不同性能和功耗要求。
XPU(X Processing Unit,各种处理器)是一个广泛用于描述各种处理器架构的缩写。它可以指代任何特定的计算架构,旨在满足特定应用程序的需求。XPU不仅仅是一个单一的处理器,而是可以包括多种异构或同构架构的处理器,通过提供灵活多样的计算解决方案,来满足不断增长的计算需求。
YOU(Your Processing Unit,你的处理器),强调个性化计算和用户体验优化,专注于提升用户界面的响应速度和定制化服务。未来会出现适合每个个体的处理器。
ZOU(Zero-Energy Processing Unit/Zero-CarbonProcessing Unit,零功耗/零碳排放处理器),专注于极低能耗计算,优化能源效率,适用于物联网设备和边缘计算,适用于环境监测、智能家居和可穿戴设备。随着计算需求的多样化和复杂化,工业软件行业正在经历一场从CPU到XPU的转型。这一转型的核心在于,不再局限于CPU的传统计算模式,而是采用一种更加灵活和全面的思维方式,以适应不断变化的技术环境和市场需求。
XPU代表了一种异构计算的概念,它涵盖了从CPU、GPU到各种专用处理器(如APU、BPU、DPU等)的广泛计算单元。这种异构计算模式能够根据不同的计算任务,动态分配和优化资源,从而实现更高的计算效率和更低的能耗。在这一转型过程中,工业软件行业需要重新审视和设计算法,以充分利用XPU架构的优势。这意味着,软件开发商需要与硬件制造商紧密合作,共同开发和优化软硬件解决方案,以实现最佳的性能和用户体验。此外,从CPU到XPU的转型也带来了新的挑战和机遇。它要求行业参与者不断学习和适应新的技术,同时也为创新和差异化提供了广阔的空间。例如,通过AI和机器学习技术的融合,可以开发出更加智能和自动化的工业软件,从而进一步提高生产效率和产品质量。
总之,从CPU到XPU的转型不仅是技术的演进,更是工业软件行业思维模式的一次重大变革。它需要行业内外的参与者共同努力,不断探索和创新,以迎接未来计算的挑战。通过这种转型,我们可以期待一个更加高效、灵活和可持续的工业软件生态系统的诞生。因此,从CPU时代迈进XPU时代,所有的代码都应该被重新检查和思考,所有的软件都应该被重新梳理和优化。
图片、文章来源:升华洞察









